Skip-Gram model use from Scratch
Many of us know are well aware of the word “Word Embeddings” in NLP courses. It is the basic foundation to the students who have opted for NLP course. Let me just brief you about this:
A word embedding is the mathematical representation of word in the form of vectors to which some linear algebra concepts can be applied to extract important features of text. Each word can be represented in the form of vector with value ranging between 0–1 and number of values in each vector can go upto any length. Ideally, it is considered that number of values(so called dimension of vector) to be taken as 300 to get optimal results.
In this post, first we will go through some basic concept of skip-gram and its working, and then the loss function and mathematics behind it and finally the code which is written from scratch.
Skip-Gram — wor2vec methods to find word embedding in which one target word is given as input and predicts the context words of the corresponding target word. Below is the illustration:

First we need to determine window size to consider how many context words we have to consider. For instance, if window size is 2 then 4 context words are considered i.e 2words on right and 2 words on left. Take a look at the illustration here:

It is an example of window size 2 and in this way we need to generate training samples for each unique word in the corpus.
Next up is what is the size of input, how do we calculate loss and update our training parameters. But, before that let’s take a overview picture of model

the input, target word is in the form of one hot encoding vector and the output will be the probabilities of each word that may occur in the context of target word. The softmax output will be our models predicted value during training and using this predicted and actual one-hot encoding values of the context words with that particular target word, we calculate loss, and then back propagate to update parameters(weight matrices) to make our model accurate. One important thing to note is that we use two matrices i.e U,V matrices in order to get the weight values(which are nothing but used in calculating word embedding values for each word in the corpus).

since our output is softmax value, we need to maximize this probability of actual context words in order to make the machine learn better. Here, C is the number of context words. uj is the softmax probability of each word and ujc* is the softmax probability of actual context words with respect to input target word. Each event(probability of context word)is considered independent, i.e why we are taking product over here. We need to know the performance of the model, for this we take negative log likelihood of the above formula to get loss function which we have to minimize. Below is the fig:


Using this loss function we backpropagate to update values of W(U matrix) and W’(V matrix).

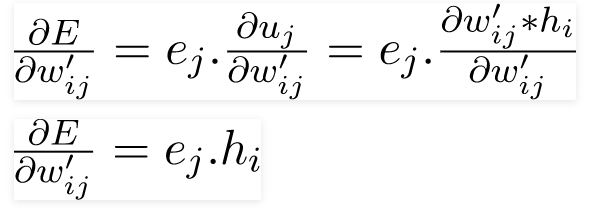
wij’ are the values of W’ matrix values. we backpropagate by differentiating with softmax layer and then softmax layer partial differentiation with respect to the values of W’ matrix.

In the above figure we updating values of W matrix:
step1: Partial differentiation of error with softmax layer.
step2: Partial differentiation of softmax layer with hidden layer.
step3: Partial differentiation of hidden layer with each values of W matrix.
So, this was the internal working of model backpropagation, lets dive into the code:
In this code, i have actually word embedded fro arabic text, u can also do with english text:


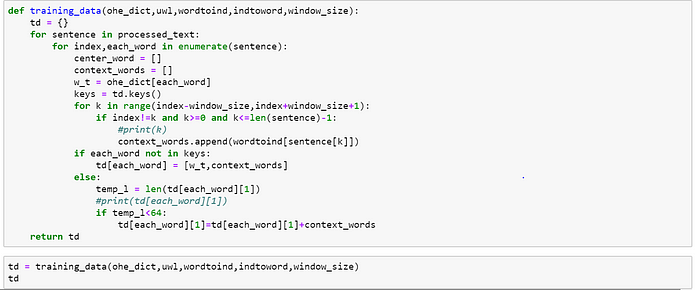
Preprocessing the text and generating training samples of each unique word in corpus.

forward propagation of data.

Backward propagation and updating parameters.

The loss for each epoch. Note: here the data is too less and very noisy so it is getting a huge loss , in reality when you have millions of corpus then neural network training gives best results.
That;s all for this blog, next blog will talk about negative sampling (method used to update only specific parameters) and Jacobian matrix, how it can be used in backpropagation.
References:
Feel free to reach me at : mudassirali2700@gmail.com
for code please visit my github here: